Devops

Planning for Failure
Technical teams often plan system changes based on how things are supposed to work and don't account for how things will break. This post explores how that plays out and how we might adjust our language to address the problem.
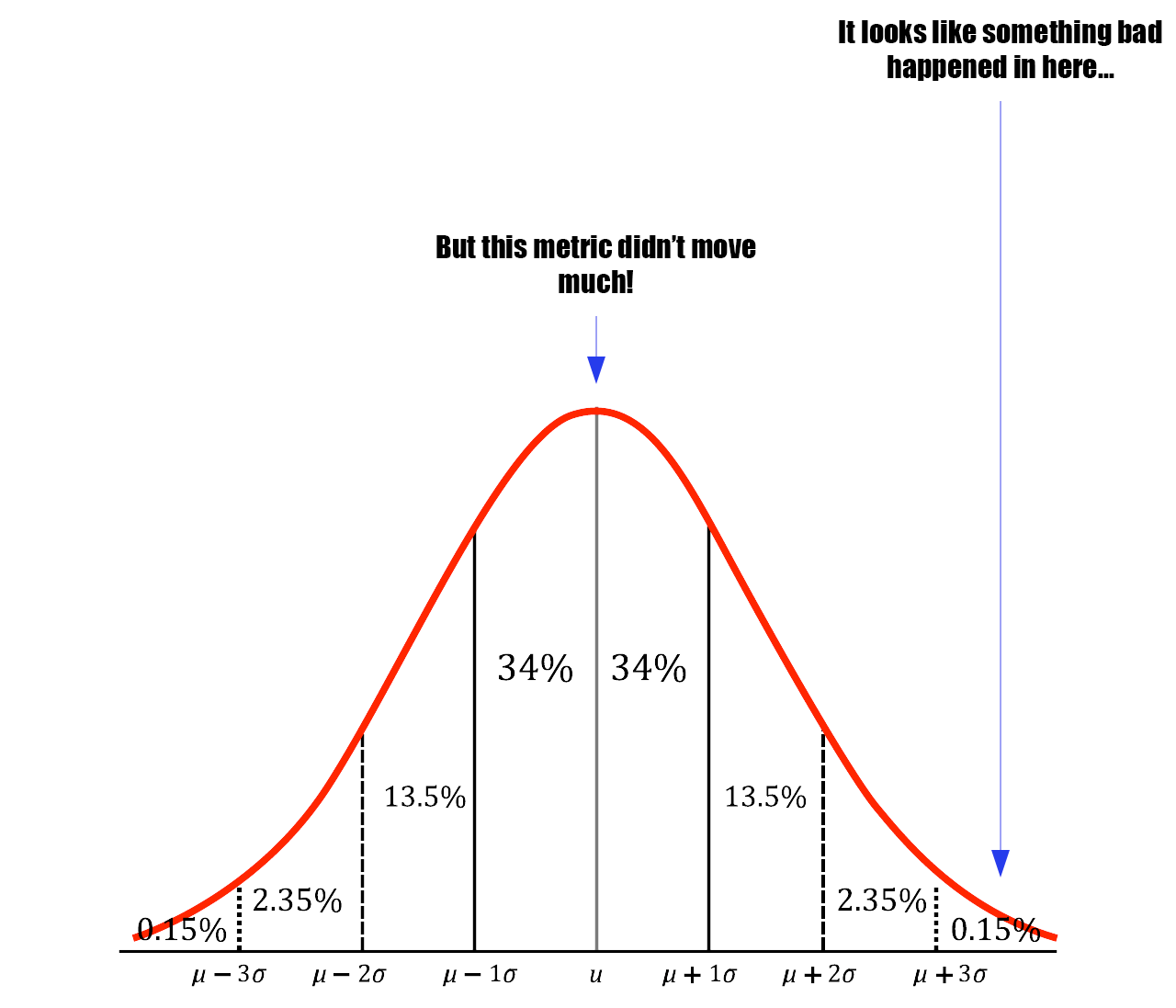
Stop relying on averages
Averages, while useful for monitoring overall system health, often misrepresent individual user experiences. To truly understand and improve user satisfaction, one must analyze data beyond averages.

Application Availability Depends on Dependencies
No SaaS application is an island. Learn how to calculate the required uptime of dependencies based on your application uptime requirements. Plus use a handy calculator!

Managers in the Theory of Constraints
A case for keeping managers out of the day to day work of the team
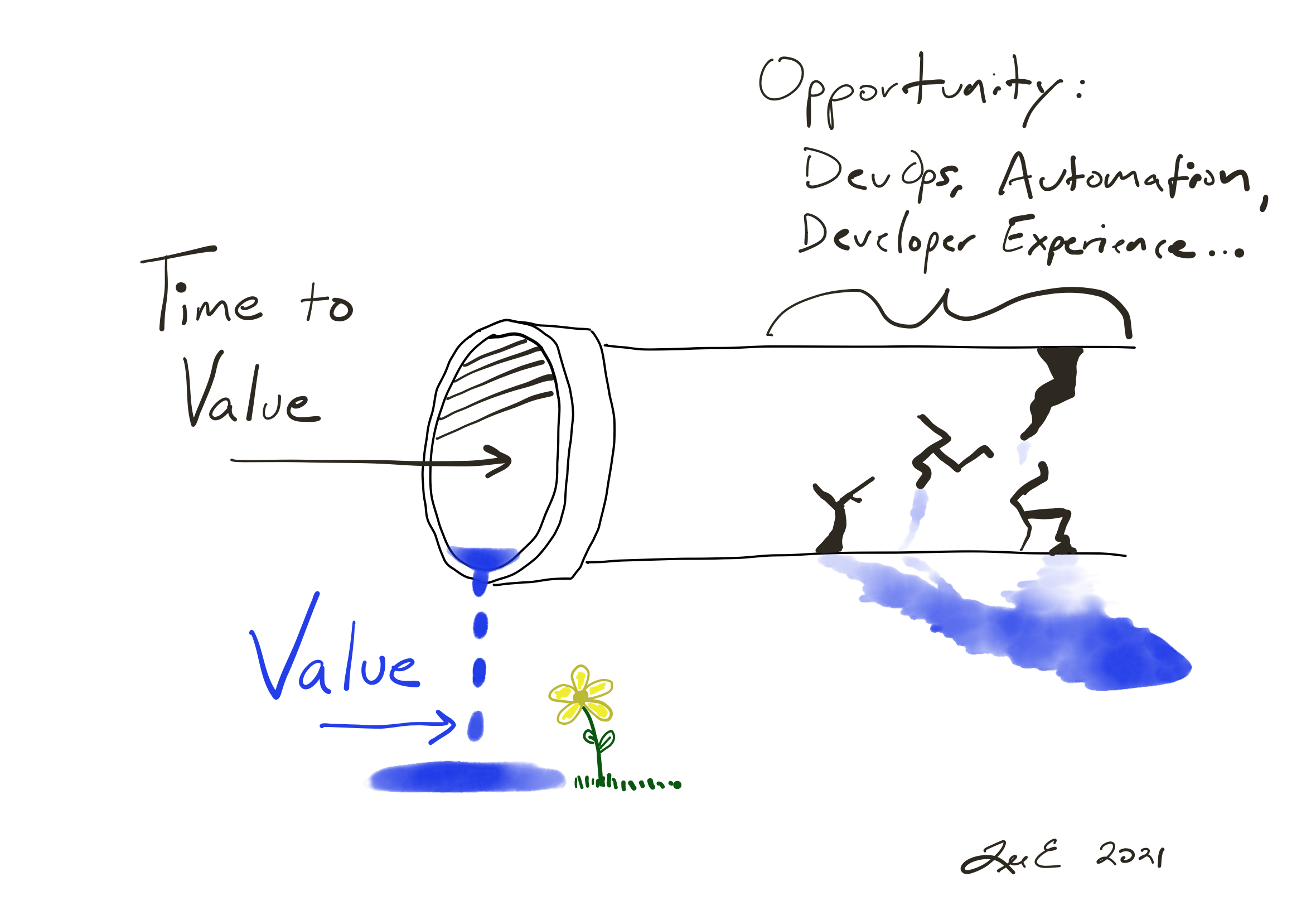
Value VS Time to Value
Why tech leaders should focus on Time to Value over Value

Test Automation Quality - Who watches the watchmen?
Getting real about the value of test automation and the quality of that code
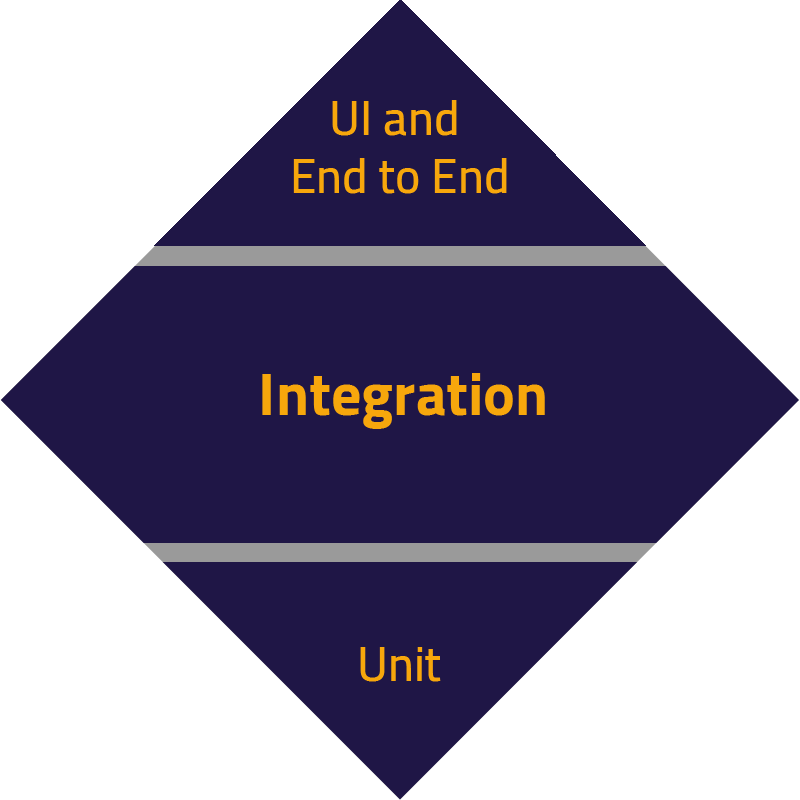
The Test Automation Diamond
Revising test automation proportions in the post-API driven world.
Saying goodbye to Slack
My takeaways after migrating from Slack to Microsoft Teams after four years of Slacking
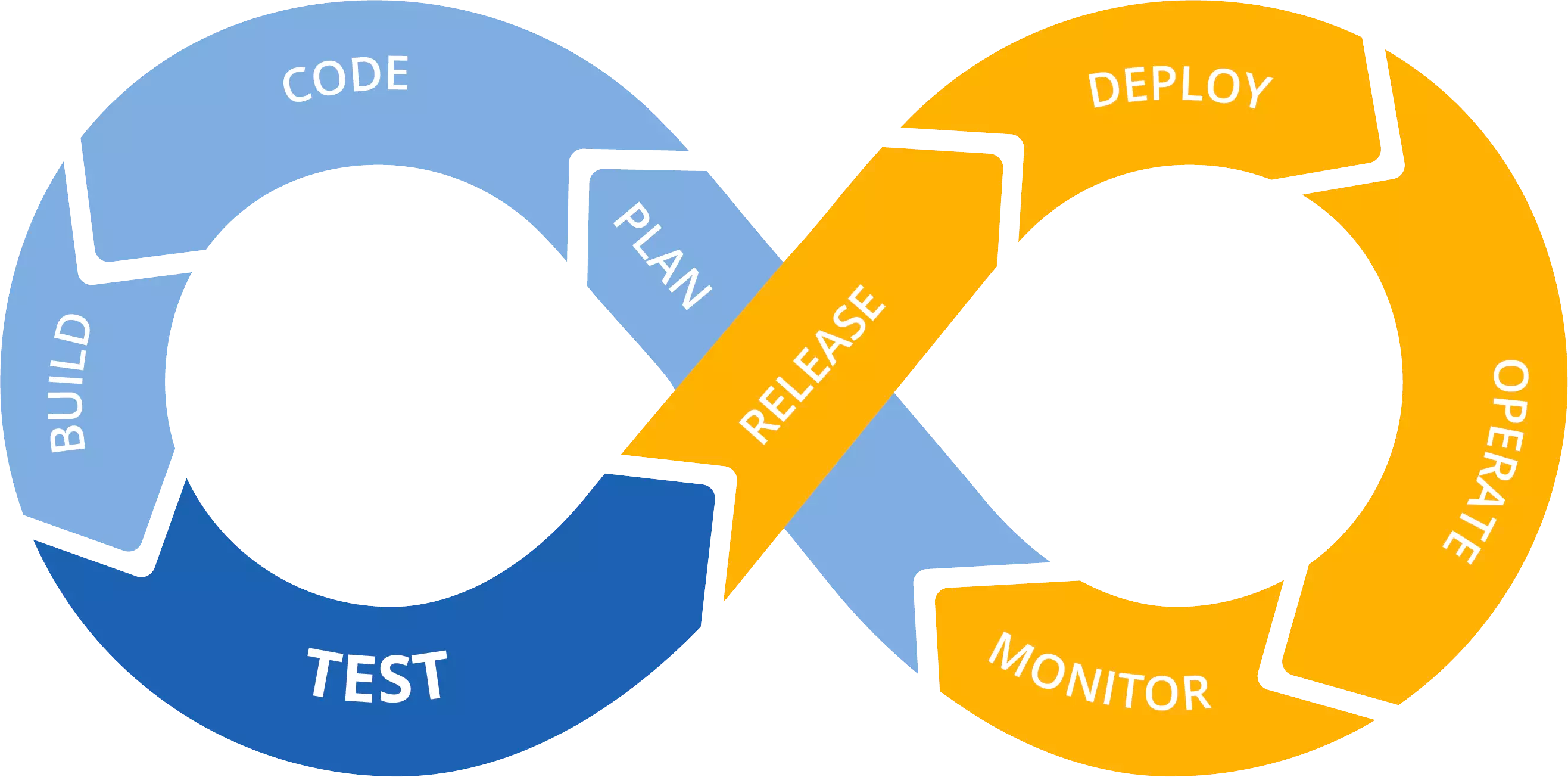
All these DevOps cycle graphics are wrong
Recognize that a Deploy and a Release are two different things and adjust your tools and process to take advantage of that fact.
Deployability: The NPS of DevOps
Including a subjective metric in your DevOps KPIs can reveal surprising depth