This article explores how Claude Code plans change when it has different amounts and types of context. It’s long been a concern of mine that losing the “why” behind decisions and only seeing how a system currently works would be harmful to quality. This was my first try at testing this empirically.
More than the results, I hope the approach I took here inspires some folks to think about ways to test our agentic coding setups better. This was pretty crude, but it’s a start.
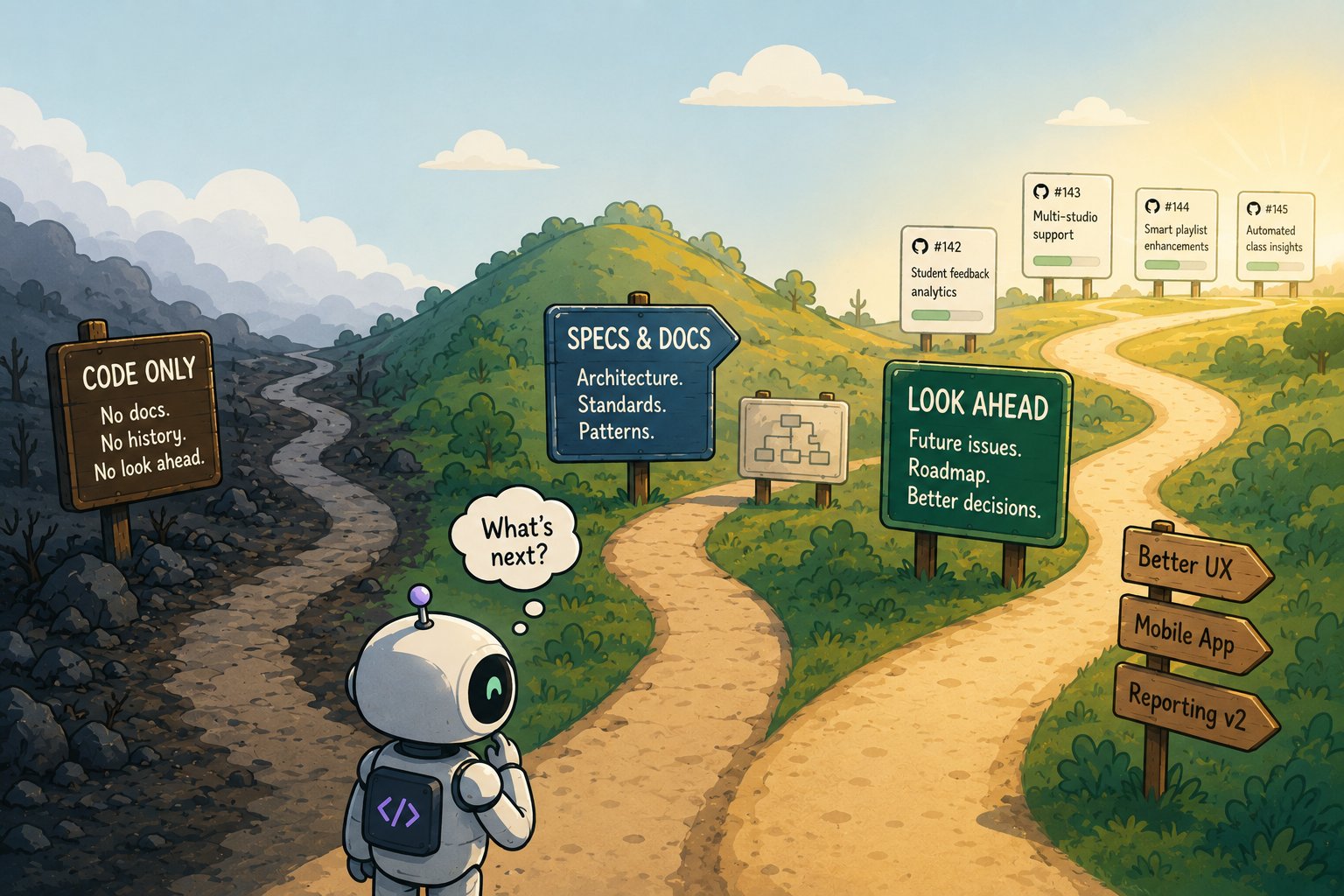
TL;DR: Having some level of documentation about how the codebase is organized and what frameworks and standards are used saves tokens and speeds up cycles. Which framework or approach you use probably doesn’t matter. Giving Claude a look ahead is the most materially impactful bit of context.
Project Context
At the end of February of this year I started building a side project with Claude Code called ClassComposer.app. I’d been reading a ton of research papers and blog posts, but nothing beats getting your hands dirty. For a while I couldn’t figure out what to build, but watching my wife plan her Yoga classes in google spreadsheets gave me a pain point to solve.
ClassComposer is a fitness class planning tool for Pilates and Yoga instructors. It helps teachers:
- Plan out different types of classes (Hatha, Vinyasa, Mat, Reformer, etc)
- Get ideas for class plans, get feedback about a plan, or build a music playlist for their class, all with AI integrations
- Manage their calendar by scheduling classes
- Get feedback from students after class
It integrates with:
- Apple and Google for calendar feeds
- Apple for music 1
- OpenAI, Anthropic, and Google for AI services
The code scale is moderate - too big to put it all in a single context window, but not enterprise size either:
| Metric | Count |
|---|---|
| Source code (project) | ~31,400 lines across 237 files |
| Python (API) | 10,587 lines / 106 files |
| TypeScript (Frontend) | 13,035 lines / 71 files |
| Astro (Marketing) | 3,035 lines / 21 files |
| HCL (Terraform infra) | 576 lines / 7 files |
| Docs (Markdown) | 2,369 lines / 13 files |
| Database | 17 tables |
| Test code | ~2,277 lines / 20 files |
| DB migrations | 27 migration files |
| GitHub issues | 130 (open + closed) |
ClassComposer has 30+ real production users that I attracted with a couple of Reddit posts. Having real users was important to me because it forces you to think about deployment downtime, database migrations, operations, logging, stability, etc. It’s too easy/tempting to skip that stuff if nobody is using the application.
The Experiment
I set up a test harness using Claude that would simulate different context scenarios. I tested three different situations:
- No documentation, no memory. I removed anything related to specifications and blocked Claude from being able to read github issue history. All it had was the code.
- My normal specification driven approach. This is how ClassComposer has evolved so far. Claude wrote specs about the database, architecture, code organization, and user facing features and the code that drives them. Claude updates these docs as part of every PR process. I describe this approach a bit in my post about supercharging user feedback.
- MemPalace hydrated from both my codebase and injected with my github issue history. I wrote a connector to github to make that possible.
I selected three random features that had already been implemented, then set up a new checkout of the ClassComposer code from right before that feature was built. I then updated the environment to match each scenario one at a time and had Claude build a plan for the feature, then compared the plans to see how they differed. Each iteration of a planned issue and test scenario started from a fresh checkout and clean context window to ensure no cross contamination.
Results
Claude Code using Opus 4.6 did a very good job of creating implementation plans in all three scenarios. However, with no documentation or MemPalace available, the planning process consumed far more tokens and took longer, even though it produced a comparable plan. I didn’t burn the tokens to actually do the code changes so I can’t say for sure the outcomes would have matched. I’ll do that next time.
There was one surprising difference that was obvious in retrospect: when Claude had knowledge of future planned user stories it incorporated them into the plan, setting things up to make that future work easier.
This was an accidental discovery. When MemPalace hydrated from github it pulled in all the issues, both the things were done before the issue I was using in the test and the ones that would come after. So while the MemPalace plan was very similar to the spec driven plan, it made subtle changes in how to approach the code, calling out how that would make the next planned code change better.
No duh
Thinking back to my years as a developer, this lesson should have been obvious from the start. We always thought about sequencing our work to make our lives easier. Epics get broken up into stories, and then we sequence the stories not just around user value, but around a sensible technical implementation path.
However, the way people approach agentic coding is very atomic and focused. I think people have been so wary of polluting the context window we didn’t think about telling the agents about the next five planned features. What I saw in this experiment makes me question that practice. Maybe we should find ways to give the agents some level of knowledge about where the code is headed so they can make better trade off decisions in how they build things.
Counterpoint
All that said, maybe in the age of agentic coding we don’t have to worry about that stuff. Who cares if the agents have to do a bit more heavy lifting in the next user story? The upside is if we end up deciding not to do that story, I haven’t polluted the code with changes that didn’t add value. Perhaps there’s some additional agility gained here that we are buying with a few more tokens?
Would love to hear your thoughts on this and whether you’ve tried giving agents a look ahead or not.
Technically I have a Spotify integration working as well, but because Spotify changed their API terms of use this year to make it impossible for new services to integrate with them, it remains disabled. Thanks, Spotify. ↩︎